
Seo Jin Park
Assistant Professor @ USC
![]()
 @usc.edu
@usc.edu
Research
Vision
The goal of my research is to make warehouse-scale parallel systems efficient so that big data applications (e.g., DNN training, analytics) can run 100–1000x faster and 10-100x cheaper.

1. Flash burst computing
Flash burst computing is motivated by two growing trends: big data and cloud computing. Today, many businesses and web services store staggering quantities of data in the cloud and lease relatively small clusters of instances to run analytics queries, train machine learning models, and more. However, the exponential data growth, combined with the slowdown of Moore’s law, makes it challenging (if not impossible) to run such big data processing tasks in real-time. Most applications run big data workloads on timescales of several minutes or hours, and resort to complex, application-specific optimizations to reduce the amount of data processing required for interactive queries. This design pattern hinders developer productivity and restricts the scope of applications that can use big data.
My research aims to enable interactive, cost-effective big data processing through “flash bursts”. Flash bursts enable an application to use a large portion of a shared cluster for short periods of time. This could allow big data applications to complete significantly faster, with cost comparable to leasing a few instances for a longer period of time. A flash-burst-capable cloud could enable new real-time applications that use big data in ad hoc ways, without relying on query prediction and precomputation; e.g., a security intrusion detection system could analyze large-scale logs from many machines in real-time as threats emerge. It could also improve developer productivity (e.g., a machine learning researcher could train models and iterate on new ideas quickly). Finally, flash bursts could reduce costs, since applications would no longer need to precompute results for all potential queries.
[5-min introduction video]
Relevant previous work:
2. Resource efficient deep learning
As emerging deep neural network (DNN) models continue to grow in size, using large GPU clusters to train DNNs or run inference is becoming an essential requirement for achieving acceptable training/inference times. However, scaling DNN training to hundreds or thousands of GPU nodes poses a significant challenge to resource efficiency. Expensive GPUs are often wasted for many reasons: waiting for network communication, bottlenecked by memory bandwidth, or operators with not enough compute intensity to utilize all GPU cores. I am interested in building new systems for machine learning that leverages fast networking to improve the efficiency of large DNN model training and inference.
Relevant previous work:
3. Distributed systems for energy efficiency
Datacenter energy consumption is growing quickly and will soon become the limiting factor for scaling our computing power. My approach to this problem is massively distributed systems. For example, a big data workload may run on slow-but-energy-efficient hardware and compensate for the slowdown with scaling to a larger cluster. Also, latency-critical applications (e.g., web services) have had to precompute for future big data queries which may or may not be used later. Flash bursts will allow transforming preprocessing for all potential queries into on-demand flash bursts, providing an opportunity for saving energy and other resources.
_
Previous projects
High-performance replication / consensus / blockchain
Consistent Unordered Replication Protocol (CURP)
Traditional approaches to replication require client requests to be ordered before making them durable by copying them to replicas. As a result, clients must wait for two round-trip times (RTTs) before updates complete. On the other hand, Consistent Unordered Replication Protocol (CURP) allows clients to replicate requests that have not yet been ordered, as long as they are commutative. This strategy allows most operations to complete in 1 RTT (the same as an unreplicated system). I implemented CURP in the Redis and RAMCloud storage systems. In RAMCloud, CURP improved write latency by ~2x and write throughput by 4x.
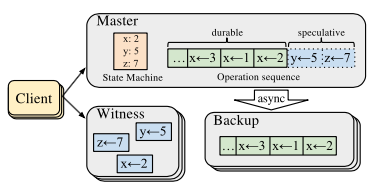
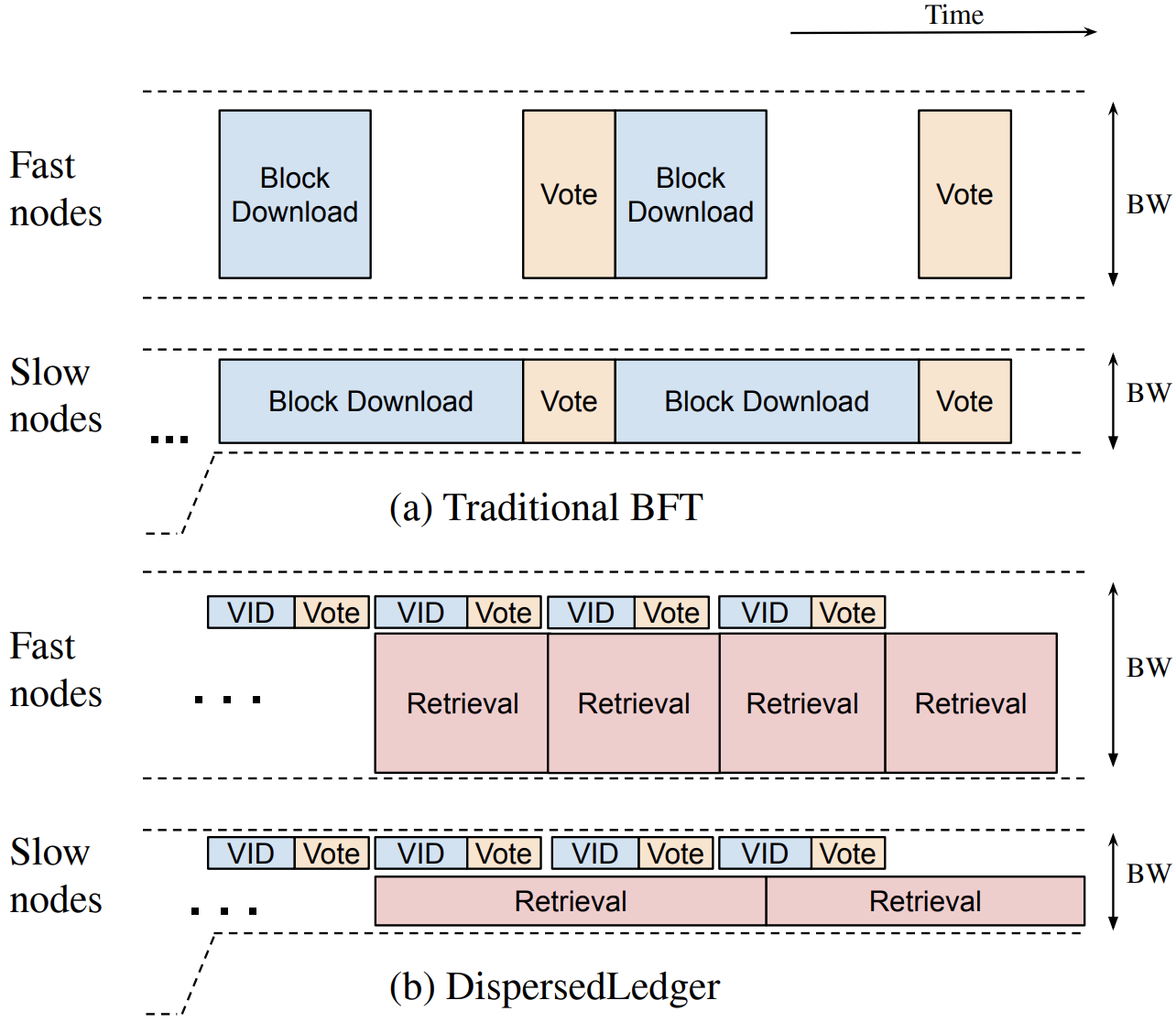
DispersedLedger
DispersedLedger is an asynchronous BFT protocol that provides near-optimal throughput in the presence of variable network bandwidth. The core idea of DispersedLedger is to enable nodes to propose and order blocks of transactions without having to download their full contents. By enabling nodes to agree on an ordered log of blocks, with a guarantee that each block is available within the network and unmalleable, DispersedLedger decouples consensus from the bandwidth-intensive task of downloading blocks, allowing each node to make progress at its own pace.
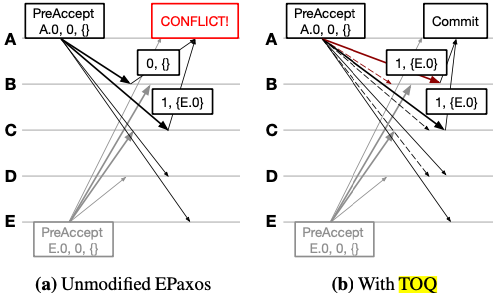
Timestamp-Ordered Queueing (TOQ)
Although the idea of exploiting commutativity for 1 RTT replication generally works well within a datacenter, it doesn't work as well in wide-area networking environments. High network delays make it more difficult to exploit commutativity since they increase the window of time during which operations can conflict with each other. Those conflicting operations must take the standard 2-RTT slow path. We mitigated this problem with a technique called Timestamp-Ordered Queueing (TOQ). With the observation that conflicts occur primarily because different replicas process operations at different times, we modified EPaxos to use synchronized clocks to ensure that all quorum replicas process a given operation at the same time. This reduces conflict rates by as much as 50% without introducing any additional latency.
ARGUS
ARGUS moved CURP's temporary backup servers from user-level processes to SmartNICs. This approach brings about two benefits: better tail latency and saving of CPU resources. Using Linux processes for backup servers results in high tail latency due to various software overheads (e.g., networking stack and context switching overhead). Using more backups makes the problem even worse since clients must wait for replication to complete at all backup servers. This undesirable effect is known to be especially problematic in public clouds. ARGUS avoids this issue by taking advantage of SmartNICs' proximity to the wire, minimal software overhead, and line-rate throughput.
Large-scale distributed DNN training
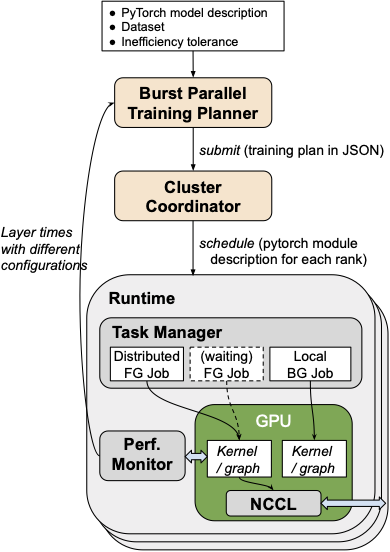
DeepPool
Scaling DNN training to hundreds or thousands of GPU nodes poses a significant challenge to scaling efficiency. At large scales, the conventional scaling strategy of increasing global batch size doesn't reduce overall training time to accuracy. For continued improvement on time to accuracy, we must consider "strong scaling" strategies that hold the global batch size constant and allocate smaller batches to each GPU. Unfortunately, small-batch training often underutilizes modern GPUs with many compute cores. Thus, we have had to make an unfortunate choice between high cluster utilization or fast training. DeepPool addresses this challenge by enabling both good cluster throughput and fast training. DeepPool incorporates two key ideas. First, I introduced a "burst parallel training planner" to dynamically adjust the number of GPUs allocated to each layer, so that layers with less parallelism can use fewer GPUs. This increases overall cluster efficiency because it frees up underutilized GPUs for use by other training tasks. Second, I propose a new collection of GPU multiplexing techniques that allow a background training task to reclaim the GPU cycles unused by the large-scale foreground task.
Large-scale low-latency data storage and analytics
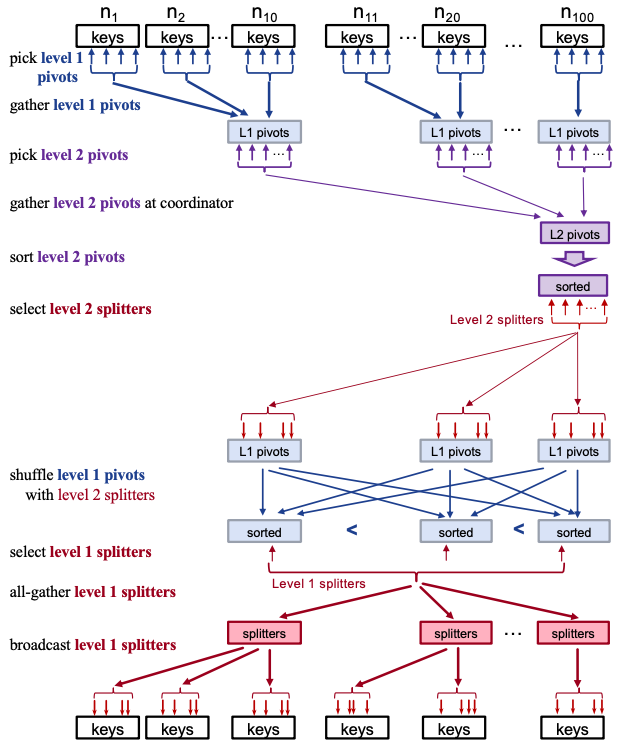
MilliSort
MilliSort is a new sorting benchmark for massively parallel computing. Since the time budget of 1 ms is extremely limited (e.g., 1 ms only allows 10000 sequential cache misses or 200 sequential RPCs), We redesigned distributed sorting from scratch to avoid cache misses and sequential RPCs. In addition, MilliSort adopted a newly invented distributed sorting algorithm that uses a hierarchical form of key range partitioning, which is 200x faster than the previous systems (100 ms -> 0.5 ms for 280 nodes). Thanks to this careful redesign, MilliSort performs very efficiently even at the extreme 1 ms timescale. MilliSort's throughput per node reaches 63.6% of the idealized upper bound, where the partitioning cost is zero and data is shuffled at full network bandwidth with perfect balance. This is on par with the efficiency of running a state-of-the-art sorting system for 100 seconds.
RAMCloud
RAMCloud is a storage system that provides low-latency access to large-scale datasets. To achieve low latency, RAMCloud stores all data in DRAM at all times. To support large capacities (1PB or more), it aggregates the memories of thousands of servers into a single coherent key-value store. RAMCloud ensures the durability of DRAM-based data by keeping backup copies on secondary storage. It uses a uniform log-structured mechanism to manage both DRAM and secondary storage, which results in high performance and efficient memory usage. RAMCloud uses a polling-based approach to communication, bypassing the kernel to communicate directly with NICs; with this approach, client applications can read small objects from any RAMCloud storage server in less than 5us, durable writes of small objects take about 13.5us.
Distributed consistency
Reusable Infrastructure for Linearizability (RIFL)
Linearizability is the strongest form of consistency for concurrent systems, but most large-scale storage systems settle for weaker forms of consistency. RIFL provides a general-purpose mechanism for converting at-least-once RPC semantics to exactly-once semantics, thereby making it easy to turn non-linearizable operations into linearizable ones. RIFL is designed for large-scale systems and is lightweight enough to be used in low-latency environments. RIFL guarantees safety even in the face of server crashes and system reconfigurations such as data migrations. We have implemented RIFL in the RAMCloud storage system and used it to make basic operations such as writes and atomic increments linearizable; RIFL adds only 530 ns to the 13.5 us base latency for durable writes. We also used RIFL to construct a new multi-object transaction mechanism in RAMCloud; RIFL's facilities significantly simplified the transaction implementation. The transaction mechanism can commit simple distributed transactions in about 20 us and it outperforms the H-Store main-memory database system on the TPC-C benchmark.
UnifiedStore
UnifiedStore is a client library layered on top of cloud storage services and presents a single storage view for hierarchical cloud storage. With simple configuration changes, UnifiedStore can switch to different underlying cloud storage services. With its novel client-side consistent caching protocol, it can also add a caching layer using another storage service that is fast but too expensive for storing all data. Distributed transactions spanning multiple underlying storage services are also supported through its novel 1-RTT client-side transaction protocol. This mix-and-match ability of UnifiedStore enables applications to have best performance at minimum cost.
Improving datacenter resource utilization
Nu
Data centers suffer from low resource utilization because their applications lack fungibility in resource use—the ability to move load quickly across servers without disrupting performance. We propose logical processes, a new abstraction that splits the classic UNIX process into many atomic units of state called proclets that can be independently and quickly migrated. Logical processes provide fungibility in resource use through this fine-grained, microsecond-scale migration. Thus, we can migrate small units of state of an application quickly, to adapt to the compute and memory resource needs of the moment.
Overload Control for us-scale RPCs with Breakwater
Modern datacenter applications are composed of hundreds of microservices with high degrees of fanout. As a result, they are sensitive to tail latency and require high request throughputs. Maintaining these characteristics under overload is difficult, especially for RPCs with short service times. Breakwater is an overload control scheme that can prevent overload in microsecond-scale services through a new server-driven admission control scheme that issues credits based on server-side queueing delay.
System performance debugging
NanoLog
NanoLog is a nanosecond scale logging system that is 1-2 orders of magnitude faster than existing logging systems such as Log4j2, spdlog, Boost log or Event Tracing for Windows. The system achieves a throughput up to 80 million log messages per second for simple messages and has a typical log invocation overhead of 8-18 nanoseconds, despite exposing a traditional printf-like API. NanoLog slims down user log messages at compile-time by extracting static log components, outputs the log in a compacted binary format at runtime, and utilizes an offline process to re-inflate the compacted logs. The lower cost of NanoLog allows developers to log more often, log in more detail, and use logging in low-latency production settings where traditional logging mechanisms are too expensive.